Time-blocking is the act of grouping certain tasks for certain times of the day, for a long time (after reading the 4 hour work week) I have just checked my email twice a day at certain times, this is an example of time blocking, another example might be that you only take calls from two until three, at a very literal level, you could schedule your whole day into allocated blocks.
It sounds simple and really, it is, well at least the planning of the Time-blocking, sticking to the time blocks without getting distracted, that is the tough bit, at least for me anyway.
Deep work is when you focus on a cognitive task and you are able to think deeply about it, the last and important part is, do it without distraction.
A side note, somewhat
I was talking to an old school mate recently about children, focus, growing up with social media, etc and we both agreed that these things had affected us too, we are of that age that we did not grow up with this tech, but still our concentration and ability has been impacted. 🙁
Combined these two teqniques can be very powerful, time blocking work for cognitive tasks and removing distractions to allow deep work may produce surprising results.
The Feynman teqnique is a method used to learn things, as part of the process, you should simplify the concept you are learning and either explain it to someone or imagine you are explaining it to a friend.
You should avoid the use of any technical or overly complicated words, if you are unable to do this, it might be a sign that you don’t understand the subject well enough.
Non AI was used in the Making of the Content Above 😁
Explaining JavaScript Closures
Im going to try to explain JS closures using the Feynman teqnique above, I might throw in an anology…
OK, so a closure in JS is a function that is inside another function, but when the inner function is called, it can still remember the variables that was set on the outer function.
My analogy, I think it could be likened to eating a lemon and your mouth watering, you eat the lemon one time, it’s gone, but if you think about eating the lemon, then your mouth still waters… 😬😁
I tthink that is pretty bad, maybe the sensation aspect will keep it mind for me.
JS cclosers can be used to create factory functions too.
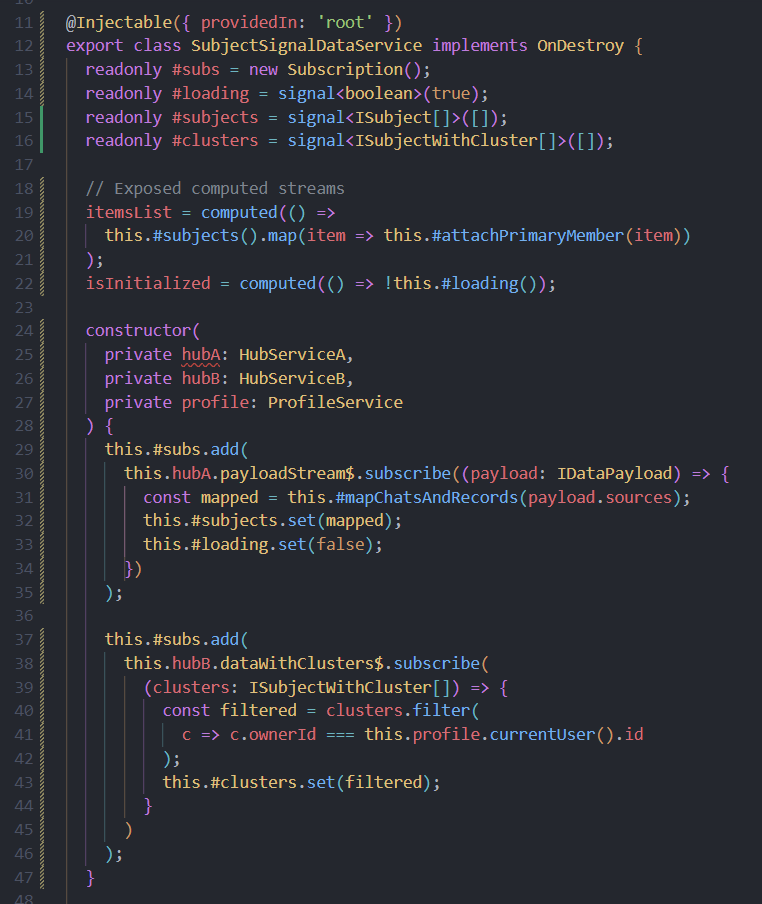
Below we have some problem code, this came from a real codebase (names changed here to protect the original code); this code just stinks. I’ve removed the imports for clarity.
This is certainly a memory jogger for me on how bad things can get. :/ The walk through is just below this code.
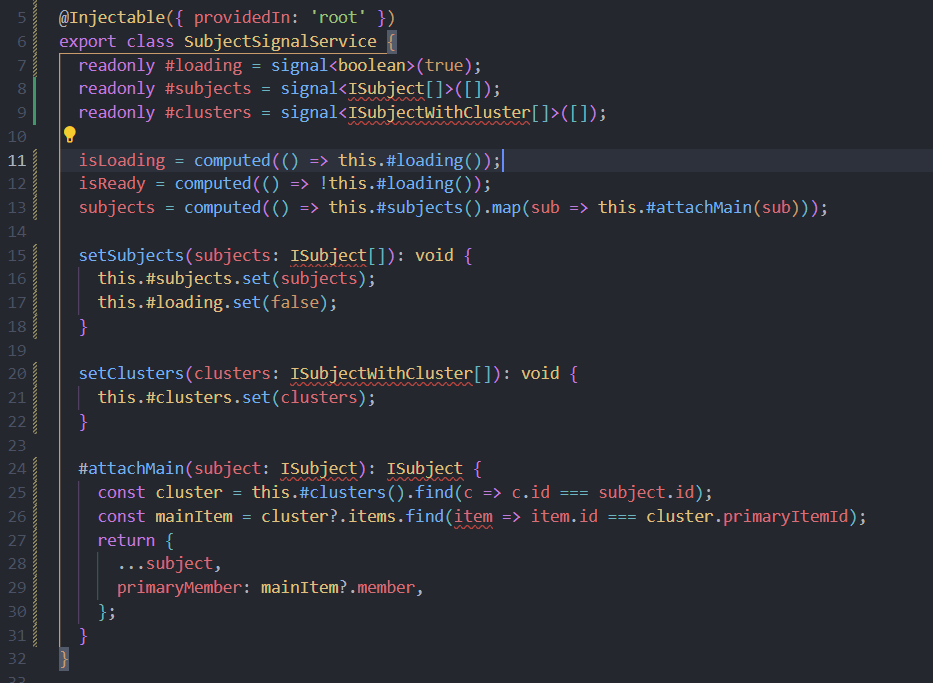
On the very next line, seeing implements “OnDestroy” in a singleton service sets off my Spidey-sense. In Angular, a root-provided service lives for the app’s lifetime, so its “ngOnDestroy” will never run—and you shouldn’t rely on it there.
Subscription field
Then we have readonly #subs = new Subscription(). Whenever I see a raw Subscription in a service, I assume something down below is wrong—manual subscription management in a singleton is almost always a code smell.
Private signals
Next come the private signals: #subject, #clusters, #loading. My understanding is that signals are meant to drive template reactivity—so keeping them private in a service feels off. Why not just expose Observables?
Computed streams
After that, we see the exposed computed fields (itemsList and isInitialised). These are hooked to the private signals, so they “work,” but computing inside the service like this (based on data set by hidden subscriptions) is unnecessary coupling.
Constructor subscriptions
In the constructor, two .subscribe(…) calls silently wire up hubA.payLoadStream$ and hubB.dataWithClusters$. Hiding subscriptions here makes it hard to reason about when or where data flows. I’d rather expose the raw streams and subscribe in a clear, visible component (e.g. AppComponent) after the service is instantiated.
ngOnDestroy
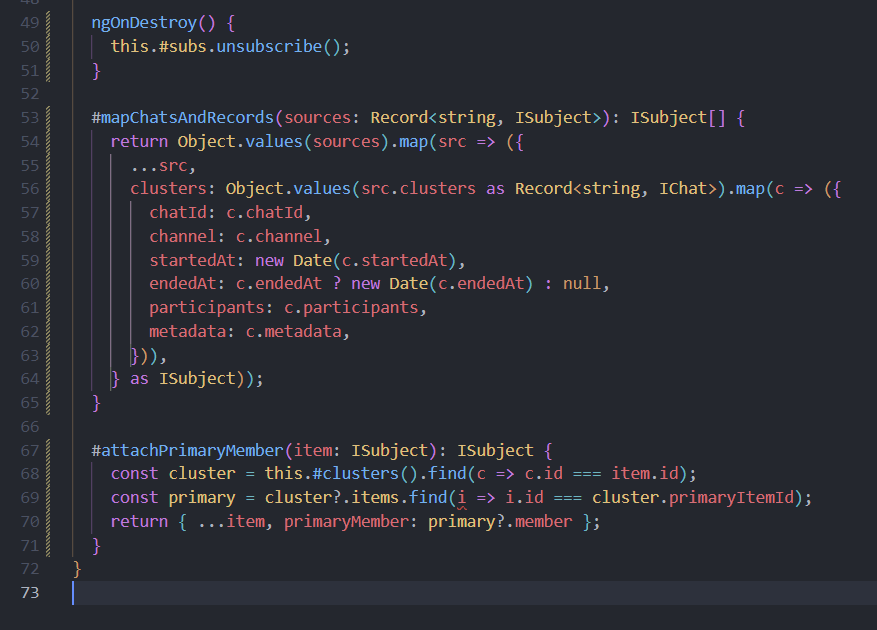
Here’s the ngOnDestroy() that unsubscribes #subs. But as noted above, in a root singleton this hook never actually fires—so it’s dead code.
Private helper methods
Finally, the private transformers (#mapChatsAndRecords, #attachPrimaryMember) do the data enrichment. Aside from their own complexity, tucking all this logic behind signals and subscriptions makes the service hard to follow.
Overall, the service mixes concerns—manual RxJS subscriptions, private signals, and computed logic—in a way that’s neither clear nor maintainable. I’d suggest refactoring toward plain Observables, exposing transformation pipelines, and handling subscription lifecycles in components rather than in a singleton service.
The Way I Would Approach This Code
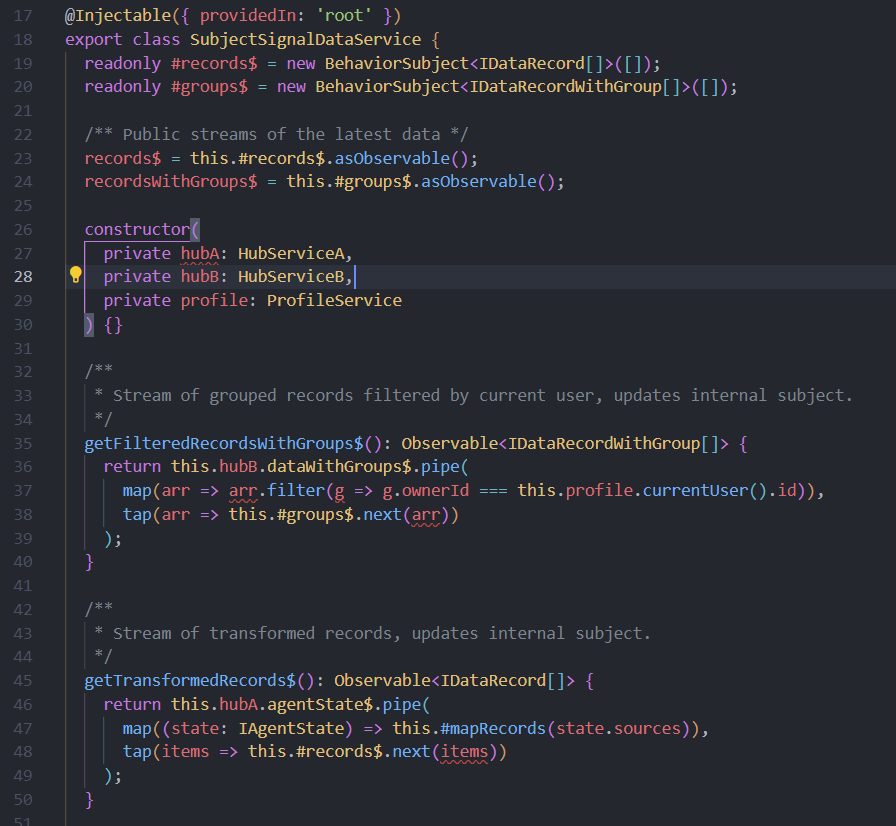
Service with just signals in (still needs more work)
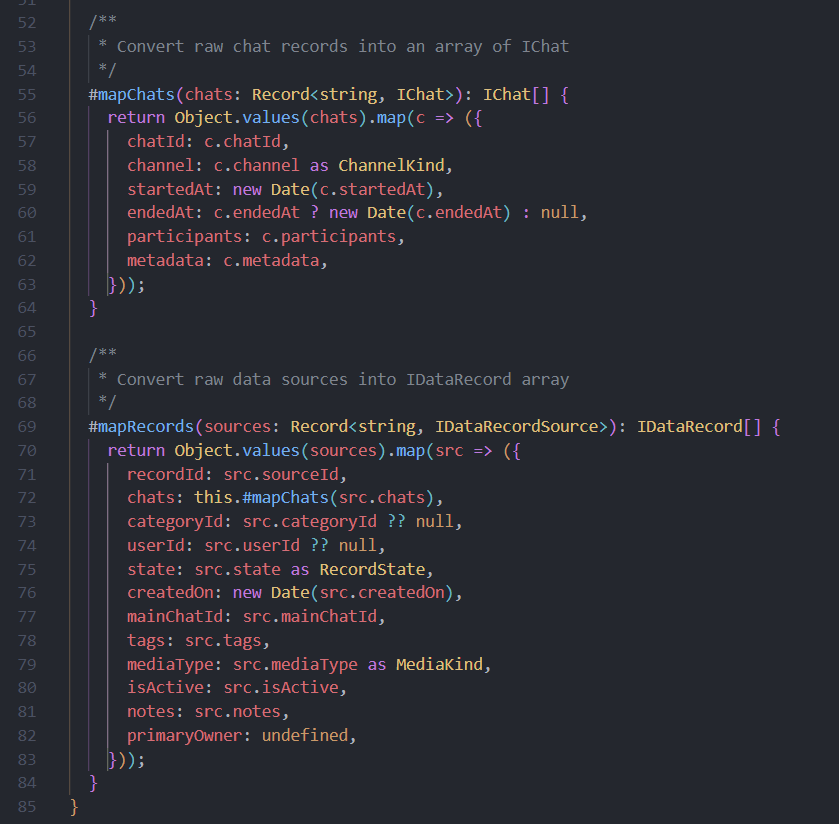
So far I’ve separated the observable streams from the signals, this let me move two of the private mapping methods out of this service (they simply transform incoming data).
Private signals remain
I haven’t cleaned up the private signals (#loading, #subjects, #clusters), but remember: signals replace zone.js change detection and should be public so templates can consume them.
Setter methods for data flow
I added setSubjects and setClusters methods, these are now called from the app component (or other orchestrating code) after subscribing to the extracted observable sources.
Second Service
This is the service that I have moved the observables into, note the naming convention, same name as the first service but just with “Data” appended.
@Injectable({ providedIn: 'root' })
export class SubjectSignalDataService {
readonly #records$ = new BehaviorSubject<IDataRecord[]>([]);
readonly #groups$ = new BehaviorSubject<IDataRecordWithGroup[]>([]);
/** Public streams of the latest data */
records$ = this.#records$.asObservable();
recordsWithGroups$ = this.#groups$.asObservable();
constructor(
private hubA: HubServiceA,
private hubB: HubServiceB,
private profile: ProfileService
) {}
/**
* Stream of grouped records filtered by current user, updates internal subject.
*/
getFilteredRecordsWithGroups$(): Observable<IDataRecordWithGroup[]> {
return this.hubB.dataWithGroups$.pipe(
map(arr => arr.filter(g => g.ownerId === this.profile.currentUser().id)),
tap(arr => this.#groups$.next(arr))
);
}
/**
* Stream of transformed records, updates internal subject.
*/
getTransformedRecords$(): Observable<IDataRecord[]> {
return this.hubA.agentState$.pipe(
map((state: IAgentState) => this.#mapRecords(state.sources)),
tap(items => this.#records$.next(items))
);
}
/**
* Convert raw chat records into an array of IChat
*/
#mapChats(chats: Record<string, IChat>): IChat[] {
return Object.values(chats).map(c => ({
chatId: c.chatId,
channel: c.channel as ChannelKind,
startedAt: new Date(c.startedAt),
endedAt: c.endedAt ? new Date(c.endedAt) : null,
participants: c.participants,
metadata: c.metadata,
}));
}
/**
* Convert raw data sources into IDataRecord array
*/
#mapRecords(sources: Record<string, IDataRecordSource>): IDataRecord[] {
return Object.values(sources).map(src => ({
recordId: src.sourceId,
chats: this.#mapChats(src.chats),
categoryId: src.categoryId ?? null,
userId: src.userId ?? null,
state: src.state as RecordState,
createdOn: new Date(src.createdOn),
mainChatId: src.mainChatId,
tags: src.tags,
mediaType: src.mediaType as MediaKind,
isActive: src.isActive,
notes: src.notes,
primaryOwner: undefined,
}));
}
}
BehaviorSubjects for further chaining
BehaviorSubjects so that other features can chain or map this data downstream without relying on the service with the signal data, I think mapping of the observables and creating a service per feature for the signal data helps a lot for readability.
Screenshots from VS code with correct formatting.
Summary
I would simplify SubjectSignalService further. You do not need both isLoading and isReady if you structure your data flow correctly. Since you now call the SubjectSignalDataService observables directly in the places where data is needed, you can manage a single loading flag there. When you subscribe and receive data, set your loading flag to true; once you call the signal setters, set it back to false.
The original service misused signals in several ways. Because its private signals were initialized with empty arrays, developers elsewhere began calling toObservable() on a public signal that was still empty. I’ll write a few short posts to demonstrate these issues and show how to avoid them.
P.S. I apologise if any of the code names do not match, I tried to squeeze the creation on this post in between patting our twin babies to sleep, screams and gurgles, across several days, etc, I hope you catch my drift, if you have children, you will. 🙂
As a software engineer, my role goes far beyond writing code that compiles. Real engineering is about solving meaningful problems, communicating clearly, and understanding the broader impact of technical decisions. That includes how code behaves, how users experience it, and how it fits into the product’s long-term goals.
This post is not a résumé or a list of frameworks. It’s a reflection of the habits, principles, and mindset that guide how I work—regardless of the tech stack.
Strong Foundations That Go Beyond Any Framework
Some of the most valuable skills I’ve learned aren’t tied to one language or library. Clean code, separation of concerns, testable design, and clear thinking apply whether you’re building in Angular, React, or a backend service. When you understand the patterns and ideas behind the tools, it becomes easier to adapt, improve, and contribute across environments.
Frontend Expertise (Angular and Beyond)
I’ve worked extensively with Angular, including modern techniques like Signals and Standalone Components. My focus is on building modular, maintainable applications with clear structure and strong reusability.
I’ve also designed systems with complex asynchronous flows using RxJS, Angular signals, and service-based facades. On projects with real-time requirements, I’ve integrated SignalR to manage multiple live data streams. These implementations typically involve synchronising authentication, API states, and socket connections to ensure components only render when the right data is available.
Although Angular is my primary frontend tool, my deeper value lies in understanding where complexity lives and how to manage it. I focus on making that complexity predictable and easy for teams to work with.
Testing and Code Quality
I treat testing as a core part of development, not a separate phase. Whether using Jasmine, Jest, or writing code with testability in mind, I aim to bake quality into every layer.
I structure components to be as lean and “dumb” as possible, using input and output bindings to keep them focused on presentation. This design makes components easier to test, easier to reuse, and easier to showcase in tools like Storybook.
I consistently include data-testid attributes as part of my markup, not as an afterthought. These allow developers to write robust unit tests and enable QA teams to create automated scripts without chasing DOM changes. For me, writing test-friendly code means thinking about the entire lifecycle of the feature—from implementation through to testing and maintenance.
Clean Code and Clear Thinking
I prioritise readability over cleverness. I write small, purposeful functions, use clear naming, and separate concerns to keep complexity under control. Where appropriate, I introduce wrappers or facades early to reduce future refactor pain and keep teams focused on business logic, not boilerplate.
The goal isn’t to write perfect code. It’s to write code that’s easy to understand for my future self, my teammates, and the business that depends on it.
Practical, Delivery-Focused Approach
I have strong experience delivering MVPs, scoping features, and shipping under real-world constraints. That includes:
Collaborating with product teams to define realistic outcomes
Delivering in small, testable increments
Communicating technical trade-offs without jargon
Using CI/CD pipelines, code reviews, and static analysis tools as daily habits
I don’t just implement tickets. I solve problems with attention to quality, context, and end-user value.
Curiosity That Drives Consistency
Books That Shape My Thinking
I read regularly across topics like psychology, marketing, and personal development. Books like Thinking, Fast and Slow, Atomic Habits, The Psychology of Money, and The Mom Test influence how I think about user experience, product decisions, and clear communication.
Staying Current with the Tech Landscape
I follow engineering blogs, changelogs, and newsletters to stay up to date without chasing trends for their own sake. I stay aware of what’s evolving—framework updates, architectural shifts, tooling improvements—and choose what to adopt with intention.
Using AI with Intention
AI is part of how I work, but never a replacement for real engineering judgment. I use tools like ChatGPT and x.ai to explore ideas, compare strategies, and generate variations, especially when brainstorming or drafting. I take time to test outputs, question assumptions, and validate anything that feels uncertain.
I also design prompts to avoid echo chambers and reduce bias. For topics where AI has limitations, I follow up with practical research. AI supports my thinking—it doesn’t make decisions for me.
What I’m Not
Knowing what you don’t do is just as valuable as knowing what you do.
I’m not a trend chaser. I adopt tools when they solve problems, not because they’re new.
I’m not a “rockstar” developer. I favour collaboration, clarity, and consistency over complexity or bravado.
I’m not tied to Angular. It’s where I’ve built deep experience, but my core practices apply across frameworks.
I don’t just complete tasks. I think about what happens next—how it’s tested, maintained, and evolved over time.
Conclusion: Building With Intention
Whether I’m writing code, reviewing work, or collaborating with product teams, I bring a thoughtful, disciplined approach. I aim to write software that is not only functional, but dependable, understandable, and ready to scale.
I’m always learning and always looking for ways to improve. If you’re building something and this approach resonates with you, feel free to reach out.
In many of the projects I’ve worked on, especially greenfield builds or early-stage MVPs, there’s often a clear need to move quickly. Teams are trying to validate an idea, meet a funding milestone, or get something usable in front of people as soon as possible. Speed becomes the focus, and that makes sense.
Over time, though, I’ve found that working fast doesn’t have to mean ignoring structure or skipping the basics. There’s a way to keep things light while still building with care. A few small habits, used thoughtfully, can actually make the work smoother and more adaptable.
This isn’t about adding unnecessary complexity or slowing things down. It’s about laying just enough groundwork to avoid getting stuck later. Whether it’s writing simple tests, organising logic cleanly, or naming things in a way that helps the next person understand what’s going on, these small choices can make a big difference over time.
The habits I tend to rely on—like clean code, functional patterns, facades, and clear data boundaries—are tools that help me stay focused and reduce friction, even when timelines are tight. I’ve found them helpful not because they’re perfect, but because they give projects a better chance to evolve without becoming hard to work with.
I try to approach software development with a sense of care rather than complexity. That means thinking not just about whether something works today, but how easily it can be understood, maintained, or adapted in the future. I am not aiming to make the code impressive. I am aiming to make it approachable.
Early Discipline
In fast-moving environments, it can be tempting to skip structure in order to deliver quickly. But I have found that a small amount of discipline early on can save a lot of time later. Simple habits like separating responsibilities, choosing clear names, or writing a basic test can make a project easier to work with without getting in the way of progress.
More than One Right Way
The approach I follow has come from experience. It is shaped by working on different types of teams and projects, and by making plenty of mistakes along the way. I do not believe there is one right way to build software, and I do not follow patterns just for the sake of it. Instead, I try to use what I have seen work in practice.
Keep Things Steady
The goal is not to slow things down or aim for perfection. It is to keep things steady enough that we can move quickly without losing confidence in what we are building.
Core Practices You Use
Over time, I’ve developed a handful of habits that help me write code that’s not just functional, but maintainable and flexible. These are simple practices that can quietly support a project’s long-term health, even when time is tight.
Unit Testing
I write unit tests to catch regressions early and give myself the confidence to change things without breaking them. Even a small set of targeted tests can help confirm that the core behaviour of a feature remains consistent, especially when requirements evolve. Testing also helps me work with fewer unknowns, which in turn speeds things up.
Snapshot Testing
I use snapshot tests to quickly detect unexpected changes in output, especially in UI components or serialised data. They’re useful for locking down the shape of something and getting fast feedback when it shifts. I treat snapshots as a lightweight safety net, not a replacement for more targeted tests.
Functional Coding
Where it makes sense, I lean toward functional patterns. Pure functions, immutability, and predictable data flow help reduce unintended side effects and make logic easier to understand. This can be especially helpful in teams, where clarity matters as much as correctness.
Facade Services
I often introduce facade services early, even in smaller projects. They create a clean boundary between parts of the application and help isolate complexity. This separation makes it easier to refactor, mock, or swap out implementations later without touching the rest of the codebase.
DTOs (Data Transfer Objects)
I use DTOs to define and control the shape of data passed between layers or components. This adds a layer of clarity and safety, especially when dealing with external APIs or shared contracts. It also helps prevent accidental coupling between unrelated parts of a system.
Clean Code
I try to write code that someone else (or future me) can easily read and reason about. That means keeping things small, naming things clearly, removing duplication where possible, and choosing simplicity over cleverness. Clean code does not have to be perfect, just understandable and practical.
Collaborative Practices and Task Refinement
I value practices like backlog refinement, shared understanding of work, and space for open technical discussion. Taking time to define and discuss tasks clearly helps avoid confusion and misalignment. In my experience, this upfront effort pays off by reducing churn later in the process.
Why These Matter Early
When working on an MVP or a greenfield build, the natural instinct is to move quickly and keep things simple. That’s a good instinct. The challenge is knowing which shortcuts are safe to take, and which ones might become costly later on.
In my experience, applying a bit of structure and discipline early on can make a big difference. It does not need to slow things down. In fact, it often speeds things up in the long run. A few well-placed tests, a clear service boundary, or a cleanly named DTO can save hours of confusion later. These small choices help keep the code understandable, predictable, and easier to adapt when the direction inevitably shifts.
Tech debt is not always about poor decisions. Sometimes it comes from good decisions made in a hurry, without enough information. That is why I try to build in a way that keeps options open. When something changes, whether it’s a new requirement, a different data shape, or another developer joining the project, I want the code to be in a state where we can respond with confidence.
Starting with habits like clean code, tests, and separation of concerns also makes it easier to scale the team. New developers can understand what is happening faster, contribute sooner, and make changes without fear of breaking things.
In the early stages of a project, things move fast. But if the foundations are steady, the pace is easier to sustain. That’s why I try to apply these practices from the beginning, even when the goal is to ship quickly.
Closing Thoughts
I have found that successful projects rarely hinge on adopting every practice under the sun. Instead, they benefit from doing a few key things consistently and doing them well. For me, that means writing clear code, adding the tests that matter, and keeping boundaries tidy. These habits are small enough to fit inside an ambitious timeline yet strong enough to keep the foundations steady.
None of this came from following a rulebook word for word. It grew out of years spent on different teams, learning what helps and what hinders when the pressure is on. Each project taught its own lessons about balancing speed with quality, and these practices are simply the ones that have proven useful again and again.
Your context may be different, and that is perfectly fine. The important part is to stay thoughtful. Choose the habits that ease your path rather than weigh it down, and keep an eye on how today’s shortcuts might feel six months from now. Build with care, even when you need to build quickly, and the next stage of the project will thank you for it.
For any team I join, these practices are a baseline. They are not extras or advanced techniques. They are the minimum I bring to help ensure the work stays maintainable, testable, and adaptable.
If your team already uses practices like clean code, testing, clear data structures, and thoughtful boundaries, that is great to see. We are already aligned, and I would love the chance to contribute.
If these habits are not yet part of your process, that is not a problem, as long as there is a clear commitment to head in that direction. I am not looking for perfection. What matters most is a shared mindset and a willingness to improve together.
If that sounds like a good fit, I would be glad to connect.
Why I’m Sharing This
Over the years, I’ve worked on a range of teams, across different industries and project styles. Some of those teams were a great fit. Others, less so. With time, I’ve learned to pay attention to what makes a good working environment for me, and where I can genuinely contribute my best.
I try to approach my work as a professional. That means being reliable, thoughtful, and holding myself to a consistent standard, even when no one is asking for it. The practices I’ve shared above are not just technical choices. They reflect how I think about quality, collaboration, and responsibility. They are part of my core values.
When these values are shared across a team, things tend to go well. Communication is easier, trust builds faster, and the work is more enjoyable. But I’ve also learned that if a team does not value these practices or is not open to them, I struggle to stay engaged. I am not at my best in environments where quality is always an afterthought or where shortcuts become the default.
This is not about judging other teams or trying to set rules for how everyone should work. Every project has its own realities. But I know from experience that I do my best work in teams that care about how things are built, not just how fast they are delivered.
That is why I’m sharing this. It is not just a list of preferences. It is an honest picture of how I work and what I bring. And it is a way of making sure that if we do work together, we are starting from a place of shared understanding and mutual respect.
I’m a senior Angular engineer with 15+ years in software development, delivering robust, maintainable applications across enterprise, startup, and independent business environments.
I specialise in building modern Angular frontends (Angular 2 through 18), with a strong focus on clean code, functional practices, and test-driven development. I lean on tools like facade services, DTOs, and layered abstractions early—even in MVPs—because I believe that sound structure now is cheaper than deep refactoring later.
Recent roles have seen me lead frontend teams through architectural overhauls, moving from tech-debt-heavy monoliths to cleaner, micro frontend-style applications. I’ve introduced stateless patterns, immutability, shared component libraries, and private registries, as well as reusable web components across codebases.
I balance delivery with thoughtful engineering, prioritising minimal, meaningful code and clear test coverage. My toolbox includes Angular signals, RxJS observables, and the ability to compose reactive logic across auth, API, and live data layers (e.g. SignalR).
Earlier in my career, I designed full-stack systems for local businesses—everything from stock control to eCommerce to custom CMS platforms. These experiences sharpened my ability to listen to users and build exactly what’s needed.
I’ve also mentored developers in Git, Agile, Docker, and Kubernetes, always encouraging simplicity and sustainable practices.
Whether I’m leading a refactor or prototyping a new feature, I bring curiosity, pragmatism, and a commitment to building things that last.
Throughout this series, I’ve been using AI tools such as ChatGPT and x.ai as structured thinking aids to help shape, explore, and clarify ideas. These posts serve both as memory joggers for myself and as a signal to companies that might need to hire me — showcasing not just my values and experience, but how I work and reason through topics.
I see AI as a companion in professional thinking, not a replacement for it. I make a point of comparing outputs across different tools, designing prompts that avoid echo chamber behaviour, and aiming for unbiased phrasing wherever possible. I also recognise that AI is not a reliable single source of truth. For certain topics, I perform additional research, validate details from multiple perspectives, and stay open to correction.
Professionalism means using tools well — and that includes using AI in a thoughtful, transparent, and intentional way.
This post was triggered by a PR comment: ‘Isn’t this wrapper overkill for MVP?’ I’ve been there before — and I’ve learned that a little early structure saves a lot of late pain.
Why I Stick to Facades and Wrappers From the Start
Currently my understanding about signals is that they should only be used when data is required in the template, so the “status” above should only be used for informing the end user, I would ideally separate out observable and signal data into different services, I have been using naming convention like “emailHubDataService” for all observable things and then “emailHubService” for any signal based things.
html
@if(isReconnecting)
<div>
Attempting to reconnect...
</div>
ts
const status = signal<'connected' | 'disconnected' | 'reconnecting'>('disconnected');
isReconnecting = computed(() => status() === 'reconnecting')
Tracking Incoming vs Outgoing Traffic
It helps to distinguish what’s being sent to the server vs what’s coming from the server. I’ve found it useful to separate these both semantically and in logging.
This is an area I have recently made some mistakes in and was informed that I had over engineered, (hence the inspiration for this post) I added a wrapper around the emailHubService and than added two new services to distinguish between incoming and outgoing calls, I understand now, that it was over engineered, my understanding just came from understanding the original hub services.
Semantic distinction:
An example of how what I wanted to achieve can be done without the separate services.
This makes tracing issues between frontend and backend a lot easier, especially when events stop flowing or are being sent with unexpected payloads.
Side Note:
The use of the “#” syntax in place of the “private” access modifier.
What I Leave Until Later
I think these should wait until there’s a clear need:
Global state libraries (NgRx, Akita)
Factories for creating hubs
Generic event buses
Central hub connection manager (unless coordinating 3+ hubs)
Observables First, Signals Later (Reminder to Self)
A quick personal rule:
Keep SignalR data as observables until it reaches the DOM — then convert to signals, if the template has a service, then I feel it is fine to convert it there too, just as long as it is not being reference around the rest of the codebase.
Why?
Observables are better for streaming, retries, and cancellations.
Signals are great for UI reactivity.
This keeps the core data flow reactive without tying it to the DOM too early.
This isn’t about gold-plating MVPs — it’s about laying groundwork that doesn’t cost much but saves me big later.
Even if nothing ships, I’d rather have clean wrappers and small abstractions than spend hours later undoing a spaghetti mess. If it all falls over? At least I didn’t build the mess twice.
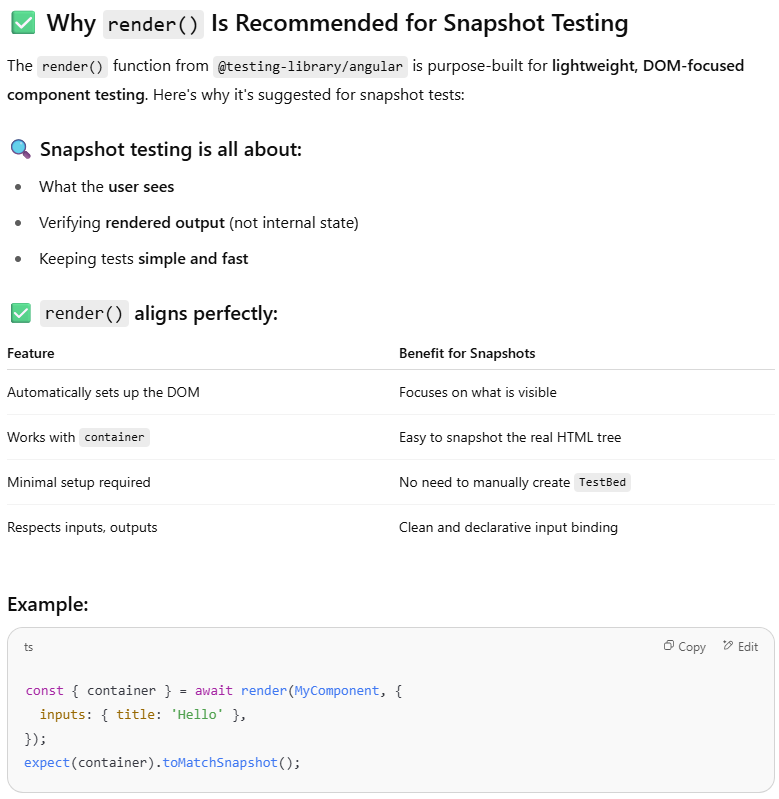
Using the “render” function for a snapshot was the suggestion of chat-gpt, it was the alternative to using the standard testbed, testbed was recommended when needing deeper integration with services and logic.
What Chat-GPT had to say
Point Two
When I first got the suggestion from GPT, it did not give me the second arg (inputs in this case) and I was getting errors telling me about my component not being recognised, I initially opted for a co-pilot suggestion and it converted the component to a string containing the selector with the inputs passed in as if I was using it in a parent component, I cannot replicate this now, the second param of the “render” function is optional either way. (I wasn’t having the best day :/ )
Point Three
I liked that I could just declare the required inputs as shown above with “render” function options, it seems a bit cleaner than the only way I currently now when you use the “Testbed” approach.